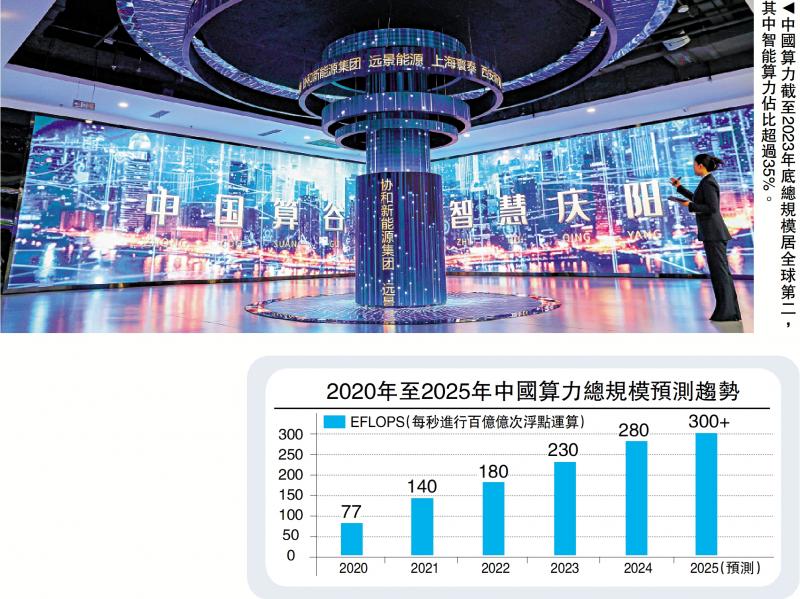
图:中国算力截至2023年底总规模居全球第二,其中智能算力占比超过35%。
当前全球算力竞争已从单一技术突破延伸至产业链自主可控、应用生态协同与基础设施全球布局的全维度博弈。中国作为全球最大的算力需求市场之一,在“数字中国”战略与“东数西算”工程推动下,国产GPU的研发突破与算力中心的体系化建设,正成为提升国家竞争力的关键抓手。
图形处理器(GPU)的发展始终与算力需求升级紧密相关。早期GPU主要用于图形加速,但随着深度学习算法的爆发,其大规模并行计算特性被重新发掘——单个GPU可提供数千个计算核心,远超传统CPU的串行处理效率,成为训练神经网络的首选硬件。据统计,当前全球AI算力中超过70%依赖GPU支撑,高端GPU芯片(如英伟达H100、AMD MI300)更因其在大模型训练中的不可替代性,成为国际科技竞争的焦点。
对中国而言,GPU的自主可控不仅是技术问题,更是国家安全与产业发展的战略命题。一方面,全球GPU市场长期被英伟达、AMD和英特尔三大巨头垄断,高端芯片对华出口限制不断加码,中国人工智能(AI)企业、科研机构及数据中心面临“算力断供”风险;另一方面,中国数字经济的快速发展催生了海量算力需求:据工信部数据,2023年中国算力总规模达230EFLOPS(每秒230百亿亿次浮点运算),全球占比超30%,其中智能算力占比超过35%,且年增速超过40%。若无法突破GPU“卡脖子”环节,中国将难以保障算力供给的稳定性与安全性,更难以在全球AI竞争中占据主动。
在此背景下,发展国产GPU既是突破“技术封锁”的必然选择,也是构建“算力─算法─数据”自主生态的关键环节。近年来,中国企业、科研院所与政策端协同发力,推动国产GPU从“可用”向“好用”迈进,为算力中心的全球竞争力提升奠定了硬件基础。
打造多层次发展体系
算力中心是GPU硬件的规模化载体,也是算力转化为生产力的关键枢纽。全球算力中心的竞争已超越单纯的“规模扩张”转向“技术先进性+应用生态+全球服务能力”的综合比拼。当前,美国依托英伟达等企业的GPU优势,构建了以互联网巨头(如亚马逊AWS、谷歌Cloud)和超算中心(如橡树岭国家实验室)为核心的算力网络,在大模型训练、科研计算等领域占据主导;中国则以“东数西算”工程为牵引,形成了覆盖通用算力、智能算力、超级算力的多层次体系,并在规模与应用场景上展现出独特优势。
从规模看,中国是全球算力增长最快的市场。截至2023年底,中国算力总规模居全球第二,其中智能算力占比超过35%(美国约30%),且数据中心总量超过8万个,机架规模超千万架。“东数西算”工程规划的8大枢纽节点(京津冀、长三角、粤港澳大湾区、成渝、内蒙古、贵州、甘肃、宁夏)已带动超4000亿元投资,通过将东部密集的AI训练需求与西部低成本、可再生能源结合,实现了算力资源的优化配置。
从技术能力看,中国算力中心正从“通用型”向“专用型”升级。针对AI大模型训练需求,头部企业(如华为、曙光、浪潮)推出液冷服务器、高速互联网络(如400G/800G光模块)与异构计算平台(即是一种整合了中央处理器(CPU)、图形处理器(GPU)和现场可程式化逻辑闸阵列(FPGA)等不同计算单元的系统),将单集群算力密度提升至每机柜1PFLOPS(每秒1千万亿次浮点运算)以上;部分算力中心开始部署国产GPU集群。
从应用生态看,中国算力中心的优势在于场景驱动的深度绑定。中国庞大的制造业、服务业与科研需求,催生了差异化的算力服务模式:在工业领域,算力中心为汽车制造(如自动驾驶仿真)、电子信息(如芯片设计验证)提供实时渲染与模拟计算;在医疗领域,支持基因测序、药物分子筛选等高性能计算任务;在科研领域,服务于气象预测、新材料研发等需要超大规模计算的场景。
双轮驱动遇四大挑战
国产GPU的发展与算力中心的建设是相辅相成的“双轮驱动”。一方面,国产GPU的性能提升直接增强算力中心的竞争力——当本土芯片能够以更低成本、更高能效满足AI训练需求时,算力中心可减少对进口硬件的依赖,降低采购与运维成本;另一方面,算力中心的大规模应用为国产GPU提供了宝贵的迭代场景——通过真实业务负载(如大模型预训练、实时数据分析)的检验,厂商能够快速发现芯片设计缺陷,针对性优化架构。
然而,两者协同发展仍面临多重挑战:
其一,高端GPU性能与国际顶尖水平存在代际差距。尽管国产GPU在中低端市场已具备竞争力,但在大模型训练所需的千亿级参数场景中,国际头部产品的算力密度(如英伟达H100的单芯片FP8算力达4PFLOPS)仍是国产芯片的2倍至3倍,且互联带宽与软件生态成熟度优势明显。
其二,软件生态的“可用性”尚未完全转化为“好用性”。尽管国产GPU兼容CUDA(英伟达开发的统一计算设备架构)降低了迁移门槛,但开发者仍需面对工具链功能不完善(如调试工具精度不足)、框架适配成本高(如PyTorch/TensorFlow对国产硬件的底层优化有限)等问题,导致部分企业因担心“迁移后性能损失”而观望。
其三,全球供应链的不确定性加剧。GPU制造依赖高端光刻机、电子设计自动化(EDA)设计工具等关键设备与软件,而这些领域目前由海外企业主导(如ASML的EUV光刻机、Synopsys的EDA工具)。若国际环境进一步收紧,国产GPU的量产进度可能受到影响,进而拖累算力中心的升级节奏。
其四,国际竞争的压力持续增大。美国通过“芯片法案”补贴本土GPU制造,并联合盟友限制先进技术出口;欧盟则通过“数字罗盘计划”推动高性能计算自主化,目标到2030年实现全球20%的高性能计算能力部署在欧洲。这些举措将进一步挤压中国在全球高端算力市场的份额。
持续深化国际性合作
面对挑战,中国需从“技术突破、生态构建、国际合作”多维度发力,推动国产GPU与算力中心形成全球竞争力。
一是强化核心技术攻关,突破高端芯片瓶颈。聚焦制程工艺(如联合国内晶圆厂攻关5nm(纳米)以下技术)、架构创新(如研发存算一体、光计算等新型计算范式)、互联技术(如提升GPU间通信带宽与延迟控制),并通过“揭榜挂帅”“首台套”等政策支持企业开展高风险研发。同时,推动国产EDA工具、光刻胶等上游材料自主化,降低供应链断供风险。
二是深化软件生态建设,提升开发者体验。加大对自主编译器、性能分析工具、AI框架适配的投入,鼓励高校与企业联合培养熟悉国产GPU的复合型人才;通过开源社区(如开放部分架构设计文档)、开发者激励计划(如提供免费算力券),吸引更多开发者参与生态共建,逐步形成“工具链完善─应用丰富─用户增长”的正向循环。
三是优化算力中心布局,强化场景驱动优势。结合“东数西算”工程,推动算力中心向专业化、绿色化方向升级——在东部枢纽(如长三角、粤港澳)布局面向实时交互的智能算力(如自动驾驶、金融风控),在西部枢纽(如成渝、宁夏)部署大规模训练集群(如大模型预训练);鼓励地方政府与企业共建行业算力平台(如医疗AI算力中心、工业仿真平台),通过定制化服务提升算力利用率与附加值。
四是深化国际合作,融入全球算力网络。在坚持自主可控的基础上,通过技术合作、标准制定、设施互联,提升中国算力中心的国际影响力。例如,可依托“一带一路”倡议,向发展中国家输出包含国产GPU的算力解决方案,拓展新兴市场空间。
GPU突破 走出自主道路
国产GPU的发展与算力中心的全球竞争力提升,是中国在数字经济时代掌握主动权的关键战役。从技术攻坚到生态构建,从本土应用到全球布局,这一过程既需要企业的创新韧性,也离不开政策的系统支持。随着国产GPU性能的持续突破、算力中心体系的不断完善,中国有望在全球算力竞争中走出一条“自主可控+开放协同”的特色道路,为AI、科学研究与产业升级提供坚实的算力底座。未来,当国产GPU的光芒照亮全球数据中心,中国必将成为数字时代不可或缺的“算力引擎”。
(作者为外资投资基金董事总经理)

 京公网安备11010502037337号
京公网安备11010502037337号